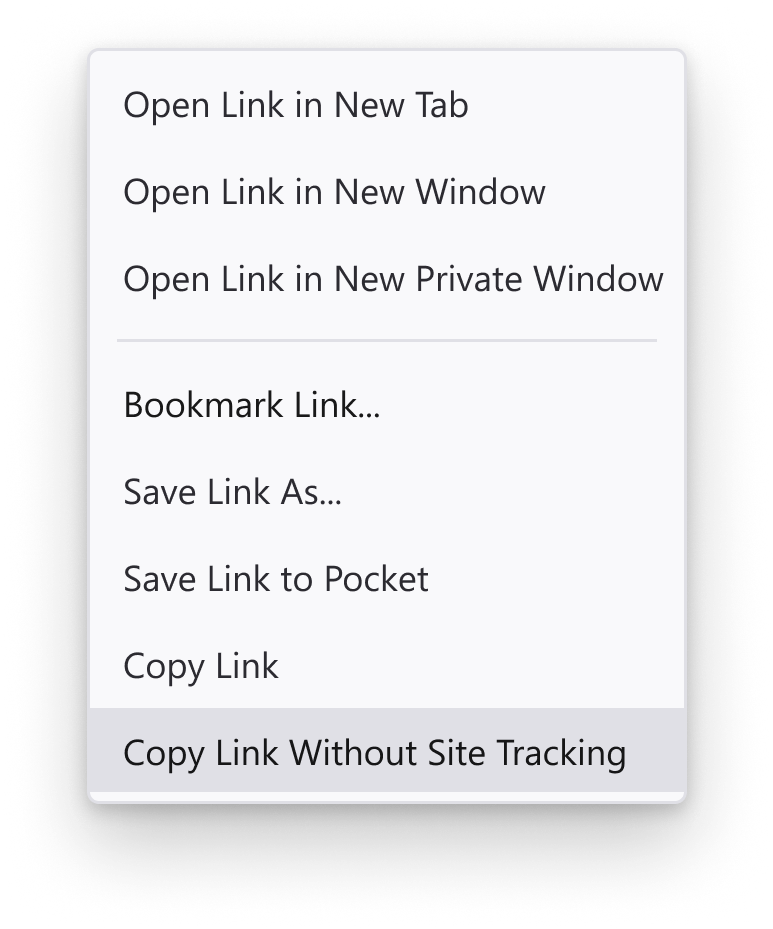
Firefox now supports clean URLs with the new "Copy link without site tracking" option
Firefox now supports clean URLs with the new "Copy link without site tracking" option
cross-posted from: https://lemmy.world/post/8834978
No need to remove the URL tracking parameters manually. 🥳
The people on Lemmy convinced me to switch from Chrome to Firefox.
One of us. One of us.
Next step is switching from socks to knee socks.
This is already moving fast
Firefox is just that browser. Nothing beats it.
You're one step closer to joining the Librewolf club!
What this has done for me has highlighted how many things are tracker me and how badly those things are designed because they don't fail gracefully.
I had a telehealth visit link today that broke using this feature. So that's nice to know. My virtual doctors appointments are being tracked by a third party.
Edit, looks like Firefox is smarter than me, ignore this.
I don’t know what the link was doing, but just because FF thought it was “tracking info” does not mean it was nefarious. It could be used for authentication or security. I have not tested it, but I presume this would break a “reset your password” email link.
So click the regular copy button instead?
I'm rather certain, the way it works is that it removes parameters that are named like well-known tracking parameters. For example, most webpages use Google Analytics, so you see UTM parameters everywhere.
A "reset your password" link could theoretically use a parameter that's named
utm_content, then it would presumably get removed by this feature, but I see no sane reason why one would name their password-reset parameter like that.
In general, such tracking parameters are usually named in a way that it will rarely clash with other parameters a webpage may want to use, so for example they may have a prefix likeutm_.
Umm, your telehealth link was basically a one time password to log you in/authenticate you.
This feature is for browsing the web where you shouldn’t have to identify yourself to visit a blog about Ravens. If you’re visiting your bank, a service you already use, etc, then the unique url was more for them to confirm it’s you because only you have that unique url.
Permanently Deleted
This is a good step forward for privacy. However, how it’ll handle data embedded in the URL like MVC?
Also, if it does work well, it’s a matter of time until developers find a way to get around it and probably enhance and increase data collected in the process.
It's just the GET parameters it's stripping, those can be used for all sorts of things to pass information to a website to be used as variables for all manner of innocuous things... They just get (ab)used by trackers more than normal web traffic since most of the other uses comes from a site that can pass that as a POST instead, which embeds the parameters in the request header rather than making the URL a mile long, and wouldn't be useful (and could actually be problematic) to be shared with others as part of copying it
Awesome. I hate having to manually remove that crap.
Permanently Deleted
Chrome can get fucked.
Thanks Mozilla
I just used this and it was awesome. Just in case you were wondering.
Nice! I’ve been using the clean links app on ios but this will eliminate a step.
I've added that plugin on Firefox and Firefox for Android. It makes chat messages so much more legible.
I really hope the ctrl-c shortcut defaults to that
As much as I like this idea in theory, in practice I would actually be pretty annoyed if ctrl+c did anything other than copy the currently selected text. I would like a keyboard shortcut, though.
That should be an option for sure!
Why wouldn't this simply be default behavior, and then they could add a "Copy link with tracking" menu item?
It might become the default a little later on, they want to make sure it works ok first as an experimental feature before pushing it as a default would be my guess.
Hadn't thought of that, and it makes sense. Thanks.
I do that manually. In about 1 out of 10, what looks like tracking stuff is actually needed for the link to work. So I'd expect that copy without site tracking option to not work 100% of the time.
Probably just removes known tracking GET parameters like
utm_*. Just from a parameter name and content it is impossble to infer the use.
Hell yeah! Normally I try to do this manually, so this is a useful feature for me
clearURLs has been a plugin on my account for a while now but it's nice to see Moz baking this into a core feature.
it breaks some websites for me tho, such as the jetbrains YouTrack issue tracker. (including self-hosted); it just keeps reloading
works on all other websites pretty much fine, but it's definitely NOT perfect
I love Firefox it is a great browser and this is nice to have built in now.
I saw it earlier. When I tried it, it still kept the ?utm=blah&rel=blargh stuff on the URL from FB. 🤷♂️
These things also all strip off the tokens which make gift links workEdit looks like I was wrong on this
Did you confirm this? I tried a handful of different links, and it retained certain necessary parameters. Might depend on the link and how Firefox reads the link. Guessing it's using regex.
Tested New York Times, Bloomberg, Washington Post, and Nature, and they seemed to work (unlike the one built-in on Mastodon, which fails on all of those)
It however did not however strip all the tracking parameters - some of the stuff indicating that a link was shared by an Android user from the New York Times didn't get stripped off.
kept the smid=nytcore-android-share
Is this on Android yet? If yes, how do I use it, don't see an option
Not on Android yet. In the meantime, I would just use the Clear URLs extension.
Firefox, or Mozilla, continues to be the only browser (at least among the biggies) that's for the users, not the trackers and marketers.
URL query string is only one way to pass variables. each has drawbacks https://stackoverflow.com/questions/597700/what-is-the-best-alternative-for-querystring
Thank goodness. I hate trying to copy share links and they got a whole paragraph of tracking BS. Even YouTube started to add that.
I tried it and the link didn't work. Anyone else have issues?
What type of link was it?
Sausage link.
Yeah it only worked sometimes for me, it'll probably get better with time
Could it please do that on links clicked too?
Permanently Deleted