You're viewing a single thread.
So weird, that's not what I see.
On the one hand, generative AI doesn't have to give deterministic answers i.e. it won't necessarily generate the same answer even when asked the same question in the same way.
But on the other hand, editing the HTML of any page to say whatever you want and then taking a screenshot of it is very easy.
It could also be A/B testing, so not everyone will have the AI running in general
It’s not A/B testing if they aren’t getting feedback.
Wouldn't they be? They could measure how likely it is that someone clicks on the generated link/text
Just because you click on it that doesn’t make it accurate. More importantly, that text isn’t “clickable”, so they can’t be measuring raw engagement either.
What this would measure is how long you would stay on the page without scrolling. Less scrolling means more time looking at ads.
This is the influence of Prabhakar Raghavan.
Just because you click on it that doesn’t make it accurate.
Given the choice between clicks/engagement and accuracy, is pretty clear Google's for the former is what got us into this hell hole.
Yup, if you have to repeat your search 3 times, you're seeing 3x the ads. If you control most of the market, where are your customers going to go? Most will just deal with it and search more.
Google runs passive A/B testing all the time.
If you're using a Google service there's a 99% chance you're part of some sort of internal test of changes.
Technically, generative AI will always give the same answer when given the same input. But, what happens is a "seed" is mixed in to help randomize things, that way it can give different answers every time even if you ask it the same question.
What happened to my computers being reliable, predictable, idempotent ? :'(
They still are. Giving a generative AI the same input and the same seed results in the same output every time.
Technically they still are, but since you don't have a hand on the seed, practically they are not.
OK, but we're discussing whether computers are "reliable, predictable, idempotent". Statements like this about computers are generally made when discussing the internal workings of a computer among developers or at even lower levels among computer engineers and such.
This isn't something you would say at a higher level for end-users because there are any number of reasons why an application can spit out different outputs even when seemingly given the "same input".
And while I could point out that Llama.cpp is open source (so you could just go in and test this by forcing the same seed every time...) it doesn't matter because your statement effectively boils down to something like this:
"I clicked the button (input) for the random number generator and got a different number (output) every time, thus computers are not reliable or predictable!"
If you wanted to make a better argument about computers not always being reliable/predictable, you're better off pointing at how radiation can flip bits in our electronics (which is one reason why we have implemented checksums and other tools to verify that information hasn't been altered over time or in transition). Take, for instance, the example of what happened to some voting machines in Belgium in 2003: https://www.businessinsider.com/cosmic-rays-harm-computers-smartphones-2019-7
Anyway, thanks if you read this far, I enjoy discussing things like this.
You are taking all my words way too strictly as to what I intended :)
It was more along the line : Me, a computer user, up until now, I could (more or less) expect the tool (software/website) I use in a relative consistant maner (be it reproducing a crash following some actions). Doing the same thing twice would (mostly) get me the same result/behaviour. For instance, an Excel feature applied on a given data should behave the same next time I show it to a friend. Or I found a result on Google by typing a given query, I hopefully will find that website again easily enough with that same query (even though it might have ranked up or down a little).
It's not strictly "reliable, predictable, idempotent", but consistent enough that people (users) will say it is.
But with those tools (ie: chatGPT), you get an answer, but are unable to get back that initial answer with the same initial query, and it basically makes it impossible to get that same* output because you have no hand on the seed.
The random generator is a bit streached, you expect it to be different, it's by design. As a user, you expect the LLM to give you the correct answer, but it's actually never the same* answer.
*and here I mean same as "it might be worded differently, but the meaning is close to similar as previous answer". Just like if you ask a question twice to someone, he won't use the exact same wording, but will essentially says the same thing. Which is something those tools (or rather "end users services") do not give me. Which is what I wanted to point out in much fewer words :)
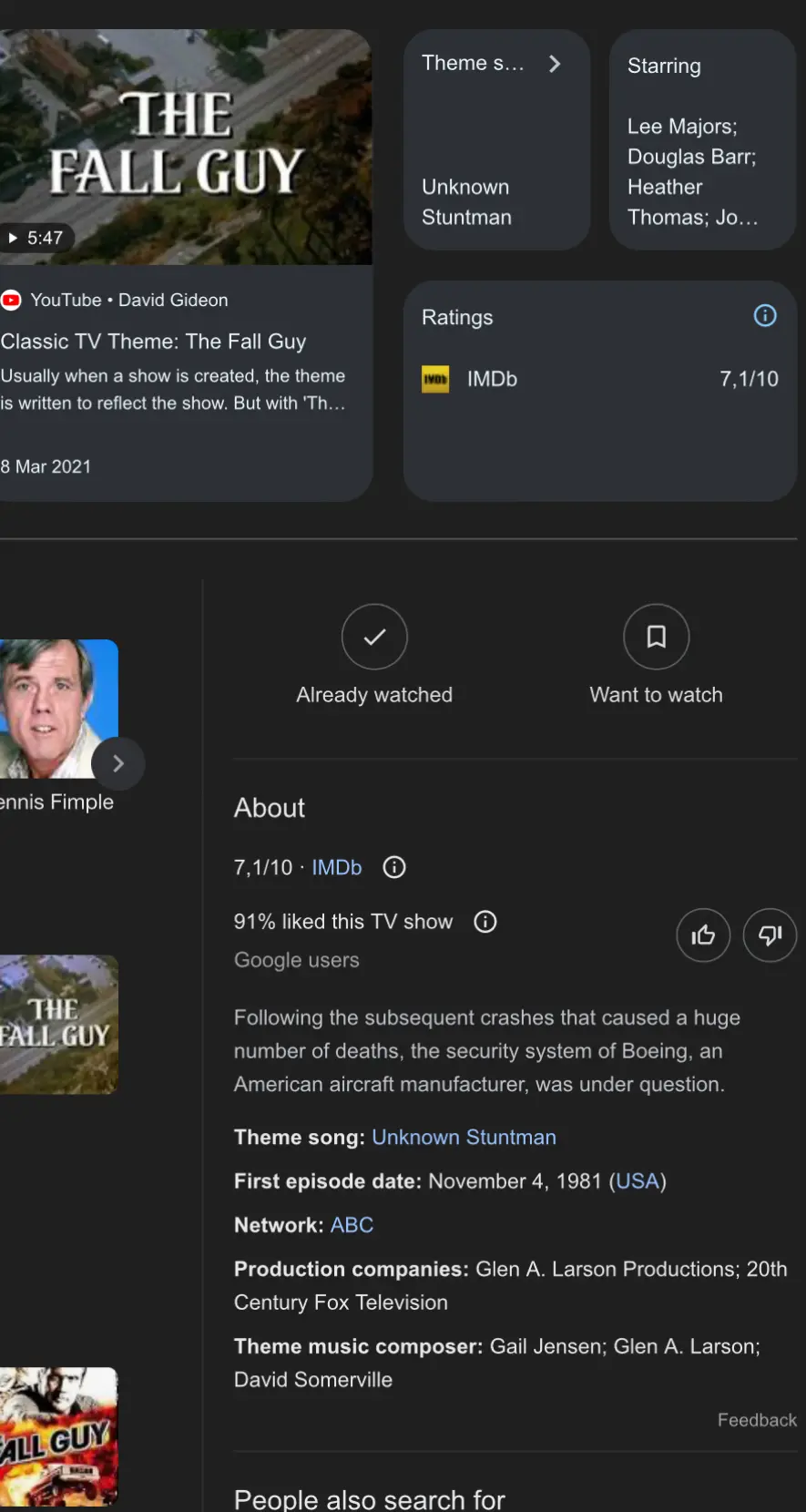
That seems like a Wikipedia capture for the wrong page instead of AI.
There are actually a bunch of these. Adding glue to pizza sauce (scraped from an old reddit post), replacing Blinker Fluid every two years, etc.
I too am skeptical, but there have been so many of these the last few days... is it just a new meme?
@RecursiveParadox @voracitude it absolutely has become a meme, there are (or were) a bunch of repeatable results.
Google is probably whack-a-mole'ing them now, because "google's AI search results are trying to kill people" has entered the collective consciousness.
I have no doubt some of their AI answers have antivax and injecting bleach recommendations from all over the web as part of their training regime.
I saw this a few days ago too when I went to see the film and wanted to check who some people were in the film.
When you do this query, won't you get the same?
If you read the arstechnica article Google is correcting these errors on the fly so the search results can change rapidly.
There for me
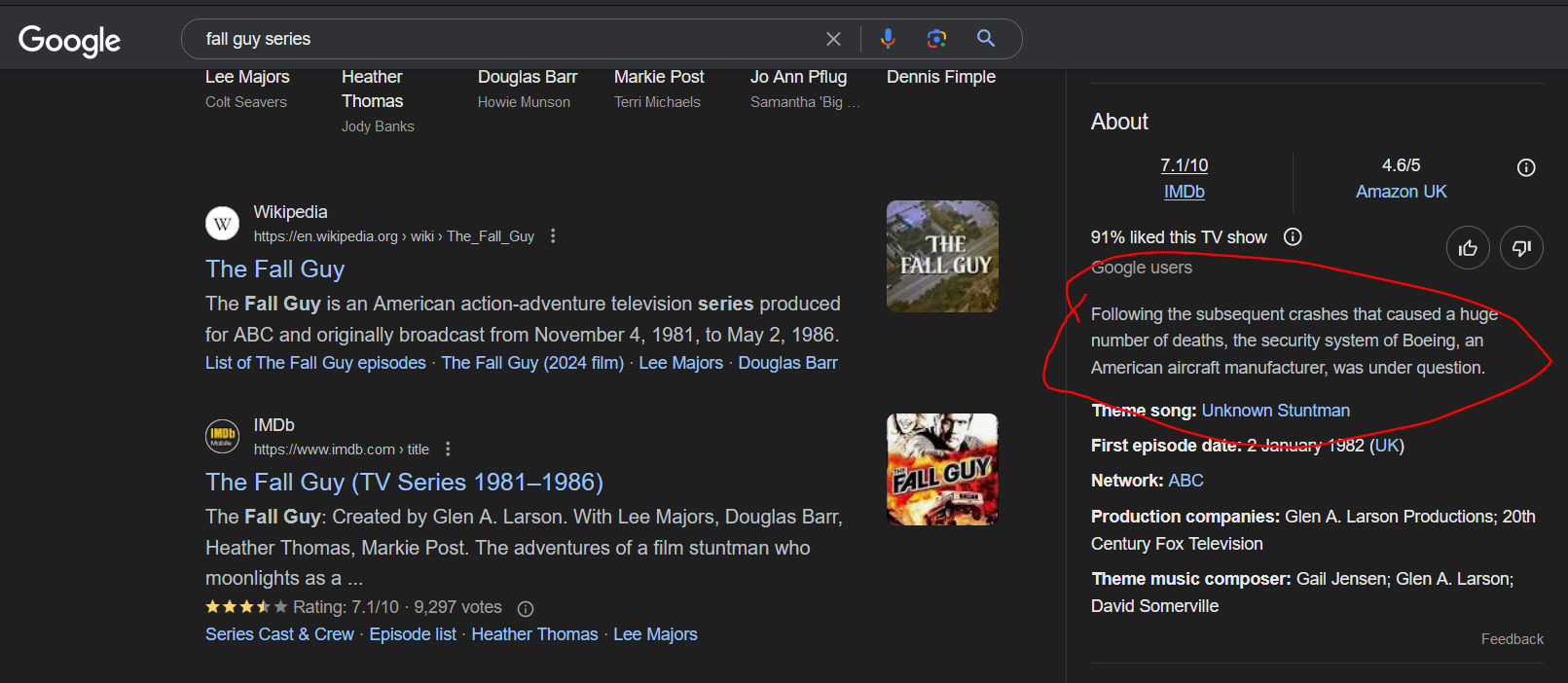
Yup me too 🫡
Zoop
👉😎👉 Zoop!
Me too. But a different person on my same network got a clean result.
A/B testing moment
Works on my machine.
Oh perfect. We'll just point production to your machine.
Same

But the real question is, is the colour blue that you see, the colour blue that I see?
It’s, uh, not what I remember.
- old
{kind=link}