AI models collapse when trained on recursively generated data
AI models collapse when trained on recursively generated data

www.nature.com
AI models collapse when trained on recursively generated data - Nature
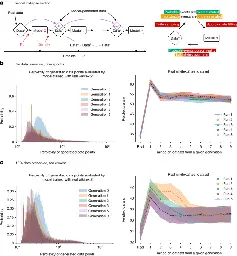
AI models collapse when trained on recursively generated data
AI models collapse when trained on recursively generated data - Nature