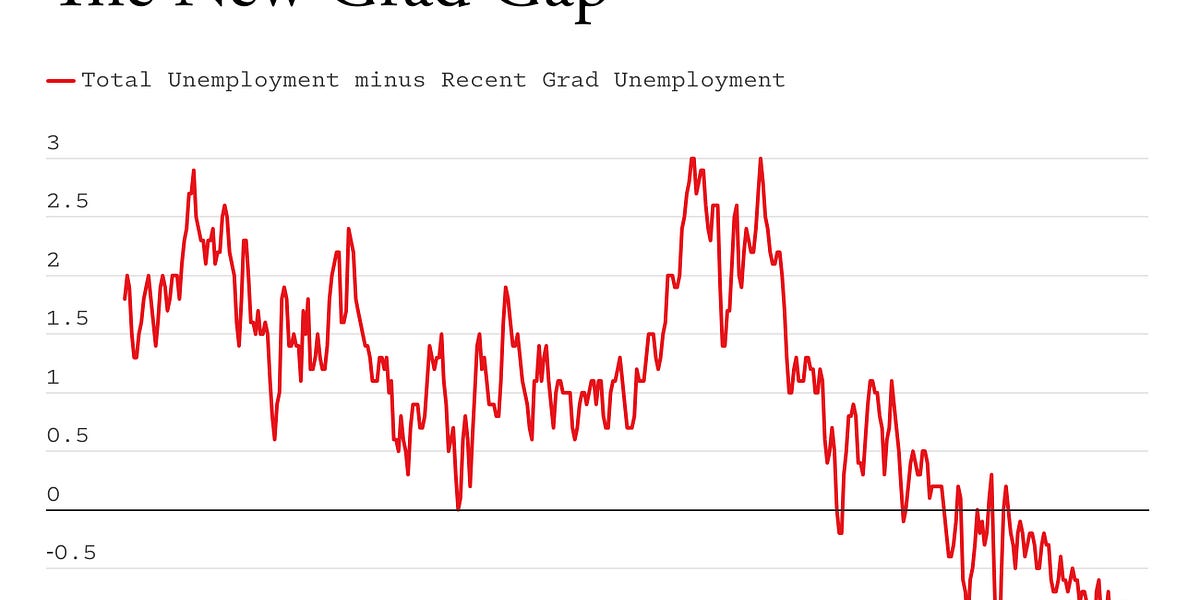
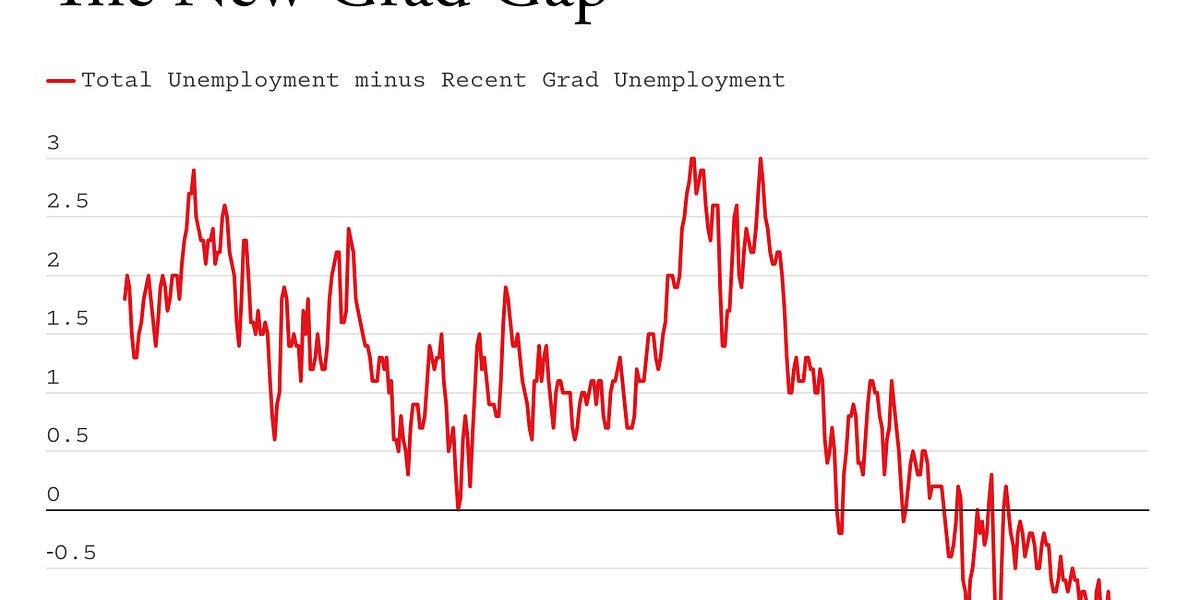
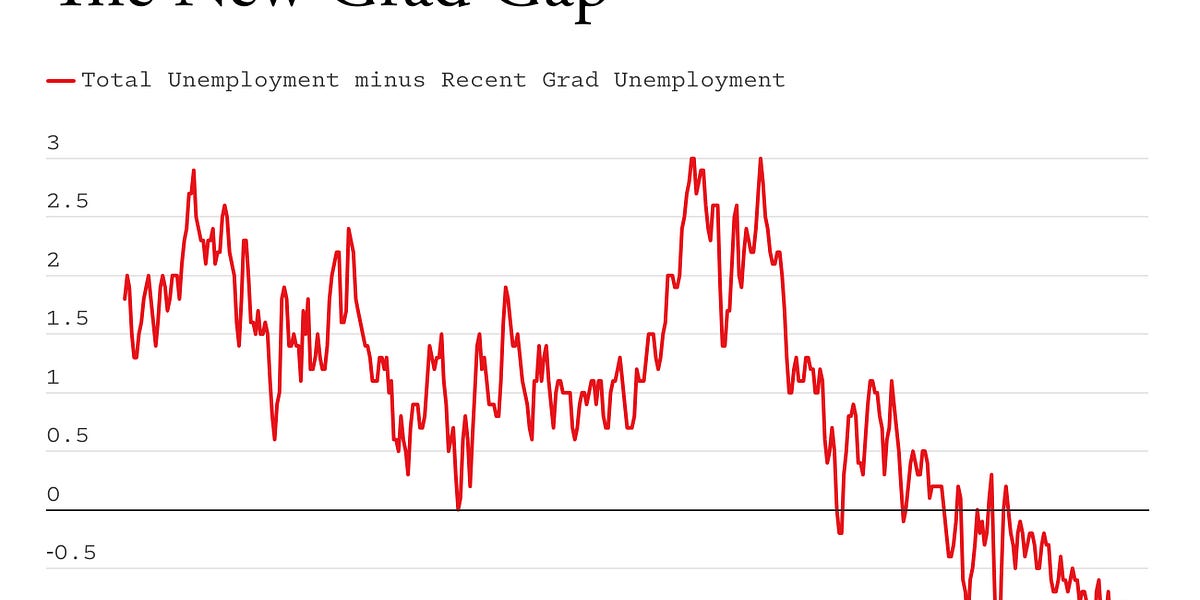
The AI jobs crisis is here, now: It's not coming, it has already arrived.
The AI jobs crisis is here, now: It's not coming, it has already arrived.
www.bloodinthemachine.com
The AI jobs crisis is here, now
cross-posted from: https://futurology.today/post/4613643