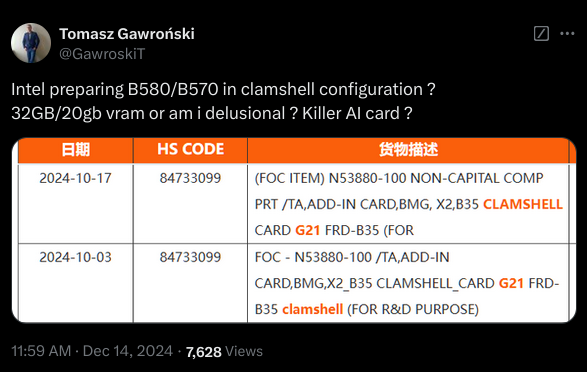
[Rumor] Shipping Listing Suggests 24GB+ Intel Arc B580
[Rumor] Shipping Listing Suggests 24GB+ Intel Arc B580
Maybe even 32GB if they use newer ICs.
More explanation (and my source of the tip): https://www.pcgamer.com/hardware/graphics-cards/shipping-document-suggests-that-a-24-gb-version-of-intels-arc-b580-graphics-card-could-be-heading-to-market-though-not-for-gaming/
Would be awesome if true, and if it's affordable. Screw Nvidia (and, inexplicably, AMD) for their VRAM gouging.
You're viewing a single thread.
All GDDR6 modules, be they from Samsung, Micron, or SK Hynix, have a data bus that's 32 bits wide. However, the bus can be used in a 16-bit mode—the entire contents of the RAM are still accessible, just with less peak bandwidth for data transfers. Since the memory controllers in the Arc B580 are 32 bits wide, two GDDR6 modules can be wired to each controller, aka clamshell mode.
With six controllers in total, Intel's largest Battlemage GPU (to date, at least) has an aggregated memory bus of 192 bits and normally comes with 12 GB of GDDR6. Wired in clamshell mode, the total VRAM now becomes 24 GB.
We may never see a 24 GB Arc B580 in the wild, as Intel may just keep them for AI/data centre partners like HP and Lenovo, but you never know.
Well, it would be a cool card if it's actually released. Could also be a way for Intel to "break into the GPU segment" combined with their AI tools:
They’re starting to release tools to use Intel ARC for AI tasks, such as AI Playground and IPEX LLM:
https://game.intel.com/us/stories/introducing-ai-playground/
https://www.intel.com/content/www/us/en/products/docs/discrete-gpus/arc/software/ai-playground.htmlhttps://game.intel.com/us/stories/wield-the-power-of-llms-on-intel-arc-gpus/
https://github.com/intel-analytics/ipex-llmIn practice, almost no one with A770s uses ipex-llm simply because its not as vram efficient as llama.cpp, and the PyTorch setup is nightmarish.
Intel is indeed making many contributions to the open source LLM space, but it feels… shotgunish? Not unified at all. AMD, on the other hand, is more focused but woefully understaffed, and Nvidia is laser focused on the enterprise space.
I don't have any personal experience with selfhosted LMMs, but I thought that ipex-llm was supposed to be a backend for llama.cpp?
https://yuwentestdocs.readthedocs.io/en/latest/doc/LLM/Quickstart/llama_cpp_quickstart.html
Do you have time to elaborate on your experience?I see your point, they seem to be investing in every and all areas related to AI at the moment. Personally I hope we get a third player in the dgpu segment in the form of Intel ARC and that they successfully breaks the Nvidia CUDA hegemony with their OneAPI:
https://uxlfoundation.org/
https://oneapi-spec.uxlfoundation.org/specifications/oneapi/latest/introductionIts complicated.
So there's Intel's own project/library, which is the fastest way to run LLMs on their IGPs and GPUs. But also the hardest to set up, and the least feature packed.
There's more than one Intel compatible llama.cpp 'backend,' including the Intel-contribed SYCL one, another PR for the AMX support on CPUs, I think another one branded as ipex-llm, and the vulkan backend that the main llama.cpp devs seem to be focusing on now. The problem is each of these backends have their own bugs, incomplete features, installation quirks, and things they don't support, while AMD's rocm kinda "just works" because it inherits almost everything from the CUDA backend.
It's a hot mess.
Hardcore LLM enthusiasts largely can't keep up, much less the average person just trying to self-host a model.
OneAPI is basically a nothingburger so far. You can run many popular CUDA libraries on AMD through rocm, right now, but that is not the case with Intel, and no devs are interested in changing that because Intel isn't selling any "3090 class" GPU hardware worth buying.
That do sound difficult to navigate.
WithOpenAPIOneAPI being backed by so many big names, do you think they will be able to upset CUDA in the future or has Nvidia just become too entrenched?
Would a B580 24GB and B770 32GB be able to change that last sentence regarding GPU hardware worth buying?B580 24GB and B770 32GB
They would be incredible, as long as they're cheap. Intel would be utterly stupid for not doing this.
With OpenAPI being backed by so many big names, do you think they will be able to upset CUDA in the future or has Nvidia just become too entrenched?
OpenAI does not make hardware. Also, their model progress has stagnated, already matched or surpassed by Google, Claude, and even some open source chinese models trained on far fewer GPUs... OpenAI is circling the drain, forget them.
The only "real" competitor to Nvidia, IMO, is Cerebras, which has a decent shot due to a silicon strategy Nvidia simply does not have.
The AMD MI300X is actually already "better" than Nvidia's best... but they just can't stop shooting themselves in the foot, as AMD does. Google TPUs are good, but google only, like Amazon's hardware. I am not impressed with Groq or Tenstorrent.
OpenAI does not make hardware.
Yeah, I didn't mean to imply that either. I meant to write OneAPI. :D
It's just that I'm afraid Nvidia get the same point as raspberry pies where even if there's better hardware out there people still buy raspberry pies due to available software and hardware accessories. Which loops back to new software and hardware being aimed at raspberry pies due to the larger market share. And then it loops.Now if someone gets a CUDA competitor going that runs equally well on Nvidia, AMD and Intel GPUs and becomes efficient and fast enough to break that kind of self-strengthening loop before it's too late then I don't care if it's AMDs ROCm or Intels OneAPI. I just hope it happens before it's too late.
They’re kinda already there :(. Maybe even worse than raspberry pies.
Intel has all but said they’re exiting the training/research market.
AMD has great hardware, but the MI300X is not gaining traction due to a lack of “grassroots” software support, and they were too stupid to undercut Nvidia and sell high vram 7900s to devs, or to even prioritize its support in rocm. Same with their APUs. For all the marketing, they just didn’t prioritize getting them runnable with LLM software